Disclaimer: This format was reverse engineered to the best of my ability. This blog article is subject to future updates or corrections if anything new is learned. Please reach out if you have any insights
Introduction
I recently found a file that Apple has started using at some point which seems to be known as a Metadata Plist based on finding files with this same format using the extension ‘.mdplist’. It seems to be different from a BPList although it seems to hold the same type of data. I’m not quite sure what the major difference is at this point and why this file might have been created as some sort of improvement or alternative to a BPList or other file types. It seems to have mainly been created for the purpose of holding data related to Spotlight, specifically ‘CSSearchableItemAttributeSet’ objects. If you have any information on this please reach out I would be interested in learning more and updating this blog to be more accurate and complete. I have written a parser in python which can be found at http://www.github.com/snoop168/mdplistlib
This library is also hosted on pypi and can be installed using the command ‘pip install mdplistlib’. Instructions for its usage can be found on GitHub.
General File Structure
The file has a magic number of 0xDEBA0001 where the 0001 might possibly be a version. The structure of the file is the following:
| Offset | Length | |
| Header | 0 | 29 |
| Root Data Element | Offset Found in Header at offset 14 (Usually 29) | Varies |
| Keys | Found in Header at offset 10 | Until end of file or offset found in header at offset 6 |
File Header Structure
| Offset | Length | Decode As | Description |
| 0 | 2 | Magic Number 0xDEBA | |
| 2 | 4 | LE UINT | 0x00010000 Possible Version (256)? |
| 6 | 4 | LE UINT | Total Length of File (Also End of Key Table) |
| 10 | 4 | LE UINT | Offset for Start of Keys (null indicates no key table) |
| 14 | 4 | LE UINT | Offset of start of root data element |
| 18 | 1 | Byte | Root Element Type (See element type Table) |
| 19 | 4 | LE UINT | End of Data Offset |
| 23 | 2 | Unknown | Unknown (usually 0x00) |
| 25 | 4 | LE UINT | End of Data Offset repeated? |
Element Type Flags (Found in Root Element Type and in Footer Entries)
When using the below table the Flag indicates the data type and how to use the 4 corresponding bytes in the footer entry. For example some data types the bytes are the offset of where in the file to access the actual data payload, but for other data types, namely the ones that can fit in the 4 bytes are directly decoded from those 4 bytes and there is no data payload located elsewhere in the file.
| Flag | Type | 4 Byte Footer Data |
| 0xF0 | List | Data Offset |
| 0xF1 | Dictionary | Data Offset |
| 0xF4 | Length Delimited Utf-8 Null Terminated String | Data Offset |
| 0xF5 | Length Delimited Unicode? String with BOM | Data Offset |
| 0xF6 | Length Delimited Binary Data | Data Offset |
| 0xF7 | CF String ? | Data Offset |
| 0xE0 | NULL | Ignore 0x00000000 |
| 0xE1 | Boolean | 0 = False, 1 = True |
| 0xE2 | Integer | Contains the INT |
| 0xE3 | Float | Contains the Float |
| 0x13 | Date (8 Bytes) | Data Offset |
| 0x23 | Long (8 Bytes) | Data Offset |
| 0x33 | Double (8 bytes) | Data Offset |
Parsing
The root data element is usually either a List or Dictionary. To parse the file you must start with the root element. You first need to know if the element is a List or Dictionary so you know long the header is. Once you decode the header, explained below you can use the lengths to break the record into its 3 parts: Header, Data, Footer. The footer is what is leftover after the data, up until the full length of the record.
Lists
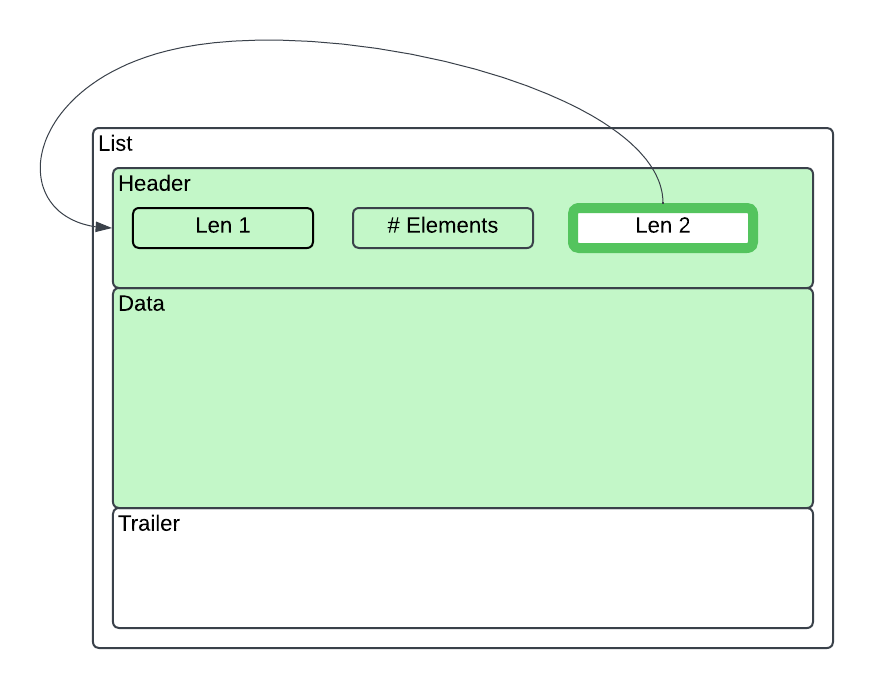
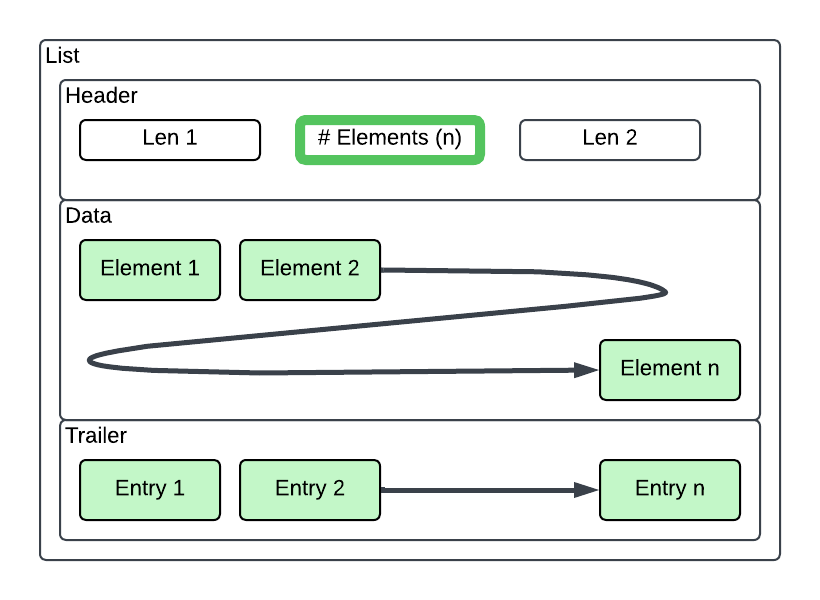
List records contain a 10 byte header and a variable length footer based on the number of records contained within it. The footer length is 5 bytes per item contained in the list.
Header
| Offset | Length | Decode As | |
| 0 | 4 | LE UINT | Length of entire record (following this offset) |
| 4 | 2 | LE UINT | Number of items contained in this list |
| 6 | 4 | LE UINT | Length of actual data portion including this header. (Trailer is found after this length up until the end of the record) |
Footer
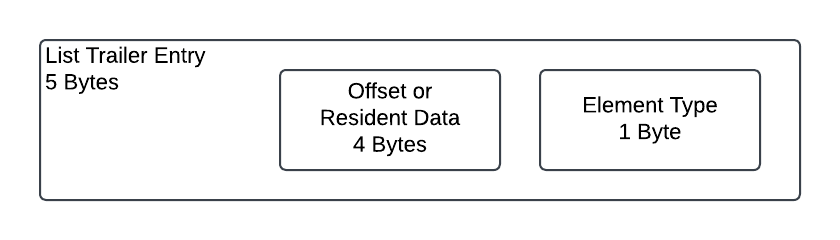
Footer entries are 5 bytes for each item contained in the list. The first 4 bytes are either the offset for the data payload in the file, or the data itself if it fits in 4 bytes. The last (5th) byte is the data type flag.
| Length | Decode As |
| 4 | UINT for Offset or data |
| 1 | Byte Flag (See Element Types Flag table) |
Dictionaries
Dictionary records contain a header and a footer like lists except the footer is actually made up of 2 sections. The first section is some sort of “counter”, while the second section is similar to the list’s footer and provides information about the records contained in the dictionary.
The dictionary has a 14 byte header, the first 10 bytes being identical to the List’s header with an added 4 byte integer which corresponds to the number of entries in the “counter” section of the footer. The number of counter records is 1 more than is decoded, implying that there will always be one of these counter records and the integer is indicating how many additional there are. It’s also possible that what is believed to be the first counter entry may just simply be padding or reserved space and the counters start after this which would account for the need to add 1 to the number decoded. The footers length is variable and is based on the number of counter records and actual data records contained within it. The purpose of the counter records is not fully understood at this time but doesn’t appear to be necessary to decode the dictionary.
The “counter” section contains 2 byte little endian integer entries. The counter always counts up until it reaches the number of elements in the dictionary. For example if the dictionary contains 5 elements you might find the counter is 0, 0, 2, 2, 4, 5, 5 (7 total counter entries 6 decoded in the header). The number of entries in this counter does not map 1-to-1 with the number of elements in the dictionary but the highest number you will see does correlate to the number of elements in the dictionary.
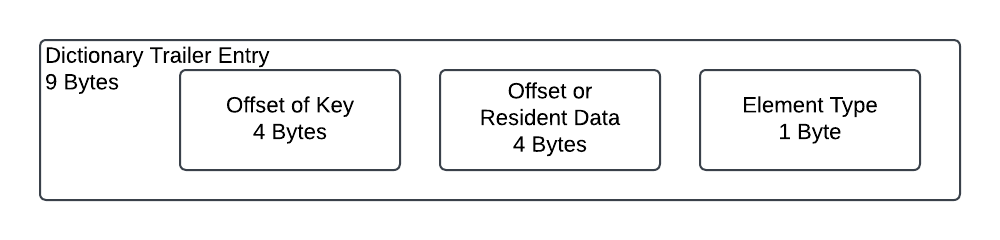
The second section of the footer is more like the list’s footer except it contains 9 bytes per record. The first 4 bytes are the offset to the key. The remainder of the footer entry is exactly the same as the list where the next 4 bytes are either the offset to the data payload or the data itself if it can be represented within the 4 bytes. The last (5th) byte is the data type flag.
Header
| Offset | Length | Decode As | |
| 0 | 4 | LE UINT | Length of entire record (following this offset) |
| 4 | 2 | LE UINT | Number of items contained in this dictionary |
| 6 | 4 | LE UINT | Length of actual data portion including this header. (Trailer is found after this length up until the end of the record) |
| 10 | 4 | LE UINT | Number of “Counter” records found in footer |
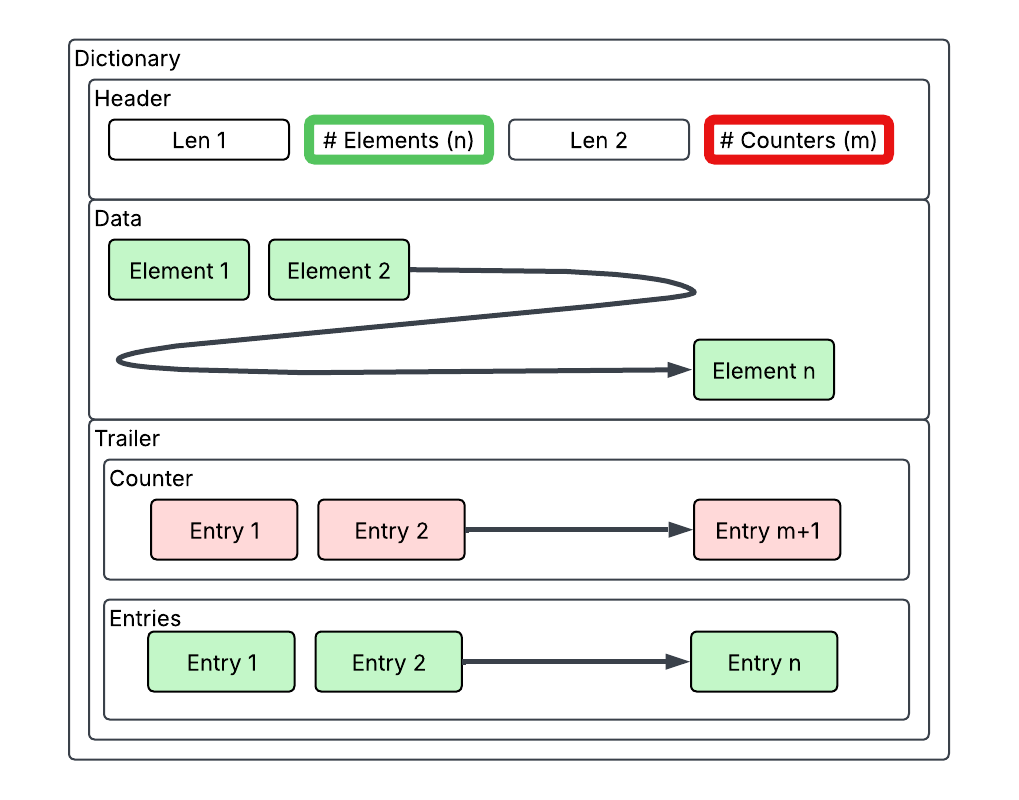
Footer
As previously explained, the footer needs to first be broken into 2 sections. The first section being the “counter”. This can be determined by decoding the value at offset 10 of the header, adding 1 and reading 2 bytes for each. The second part of the footer is similar to the list’s footer except each entry is 9 bytes for each item contained in the dictionary. The first 4 bytes are the offset to the key relative to the top of the key table. The remainder of this footer entry is the same as the list where the second 4 bytes are either the offset for the data payload or the data itself if it fits in 4 bytes. The last byte is the data type flag.
| Length | Decode As |
| 4 | UINT for Offset to key (relative to the start of the key table) |
| 4 | UINT for Offset of data |
| 1 | Byte Flag (See Element Types Flag table) |
Keys
The keys used within the entire file are located in a single table at the end of the file. The start of the keys can be located by decoding 4 bytes at file offset 10 in the file header. The keys continue until the end of the file which can also be determined by decoding 4 bytes at file offset 6 in the file header.
The keys are arranged with a 2 byte length designation, followed by the string followed by null terminator. (The null terminator is not included in the length decoded so it must be accounted for separately.
| Length | Description |
| 2 | Length of string to follow |
| Found above | String (UTF-8) |
| 1 | 0x00 Null Terminator |
Where to find this data
If you search a phone for files with the extension .mdplist you will find several examples of this file, but the ones containing more artifacts are embedded within other files. You can do a raw bytes search for the hexadecimal characters DEBA0001 and you will likely find numerous results. You can quickly extract one by reading what would be offset 6 then sweeping that number of bytes starting at the beginning of the DEBA0001 header. You should end up after the null byte after the last key in the key table.
You will also find many skg_archive.V2.* files at the below path.
/private/var/mobile/Library/Spotlight/CoreSpotlight/SpotlightKnowledge/index.V2/keyphrases/[File Protection Class]/skg_archive.V2.*
The above files are BPList files in NSKeyedArchiver format. If you deserialize the PList you will find a list containing CSSearchableItem dictionaries. Within each entry you will find an “attributes” key and within that a “container” key. Within the container element you will see the data and the “DEBA0001” header. If you decode this using the python library you will find a List containing additional data including a nested dictionary. Within this dictionary you will find many keys and values consistent with a CSSearchableItemAttributeSet related to Spotlight including keys such as _kMDItemSnippet, kMDItemRecipientEmailAddresses, kMDItemAuthorEmailAddresses, kMDItemContentCreationDate, _kMDItemDomainIdentifier.
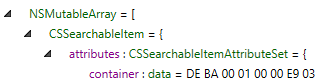
So far I have found what appears to only be indexed emails in these files. Some of this data is likely to be also found in the form of full emails in the extraction or other indexed data in the spotlight store.db. The significance of the files found in this location is that they may be located in a BFU extraction. For example I was able to locate many records in a BFU extraction of an iOS 17.1 device. I have written a plugin for iLEAPP for this artifact as well which can be found under the option “Spotlight [SKG Archive]”